
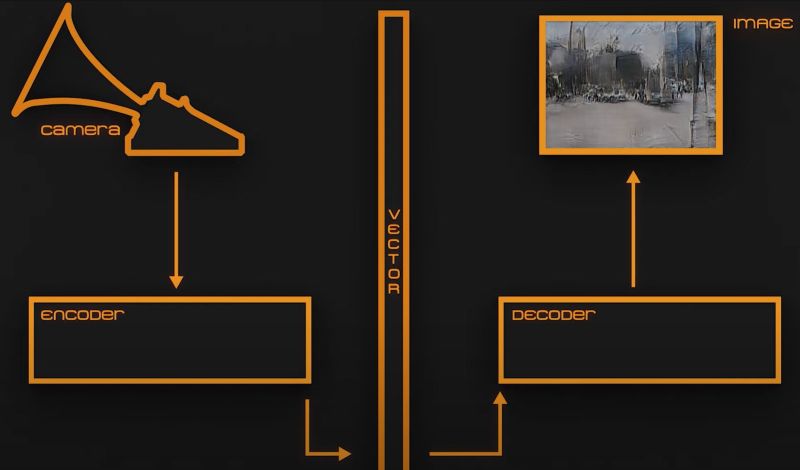

When we see a photograph or photo of a scene, we can likely imagine what sounds would go with it, but what if this gets inverted, and we have to imagine the scene that goes with the sounds? How close would we get to reconstructing the scene in our mind, without the biases of our upbringing and background rendering this into a near-impossible task? This is essentially the focus of a project by [Diego Trujillo Pisanty] which he calls Blind Camera.
Based on video data recorded in Mexico City, a neural network created using Tensorflow 3 was trained using an RTX 3080 GPU on a dataset containing frames from these videos that were associated with a sound. As a result, when the thus trained neural network is presented with a sound profile (the ‘photo’), it’ll attempt to reconstruct the scene based on this input and its model, all of which has been adapted to run on a single Raspberry Pi 3B board.
However, since all the model knows are the sights and sounds of Mexico City, the resulting image will always be presented as a composite of scenes from this city. As [Diego] himself puts it: for the device, everything is a city. In a way it is an excellent way to demonstrate how not only neural networks are limited by their training data, but so too are us humans.
Blind Camera: Visualizing a Scene From Its Sounds Alone
Source: Manila Flash Report





0 Comments